
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 타임리프Unescape
- 타임리프기본객체
- 정보처리기사
- 타임리프 표현식
- 타임리프Escape
- 정처기실기요약
- 타임리프날짜
- spring
- 개체관계모델
- 정보처리기사실기요약
- HelloWorld출력
- mybatis
- 타임리프 특징
- 이클립스없이cmd
- MySQL설치순서
- 타임리프SpringEL
- 타임리프URL
- mysql설치하기
- 정보처리기사실기
- cmd에서java파일실행
- 정처기실기
- thymeleaf
- 타임리프유틸리티객체
- java
- ER모델
- 스프링부트설정
- 타임리프변수
- git
- mysql다운로드
- mysql
- Today
- Total
ye._.veloper
[ 정보처리기사 실기 요약 ] 2. 데이터 입·출력 구현 본문
( 1 ) 데이터베이스 개요
☁ 데이터저장소
· 데이터들을 논리적인 구조로 조직화하거나, 물리적인 공간에 구축한 것을 의미
· 논리 데이터저장소 : 데이터 및 데이터 간의 연관성, 제약조건을 식별하여 논리적인 구조로 조직화한 것
· 물리 데이터저장소 : 논리 데이터저장소를 소프트웨어가 운용될 환경의 물리적 특성을 고려하여 실제 저장장치에 저장한 것을 의미
☁ 데이터베이스(DB ; DataBase)
· 공동으로 사용될 데이터의 중복을 배제하여 통합하고, 저장장치에 저장하여 항상 사용할 수 있도록 운영하는 운영 데이터
| 구 분 | 정 의 |
| 통합된 데이터 (Integrated Data) | · 자료의 중복을 배제한 데이터의 모임 |
| 저장된 데이터 (Stored Data) | · 컴퓨터가 접근할 수 있는 저장 매체에 저장된 자료 |
| 운영 데이터 (Operational Data) | · 조직의 고유한 업무를 수행하는데 반드시 필요한 자료 |
| 공용 데이터 (Shared Data) | · 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료 |
☁ DBMS (DataBase Management System ; 데이터베이스 관리 시스템)
· 사용자의 요구에 따라 정보를 생성해주고, 데이터베이스를 관리해주는 소프트웨어
· 필수 기능 3가지 (정조제)
| 정의 (Definition) 기능 | · 데이터의 형(type)과 구조에 대한 정의, 이용 방식, 제약 조건 등을 명시하는 기능 |
| 조직 (Manipulation) 기능 | · 데이터 검색, 갱신, 삽입, 삭제 등을 위해 인터페이스 수단을 제공하는 기능 |
| 제어 (Control) 기능 | · 데이터의 무결성, 보안, 권한 검사, 병행 제어를 제공하는 기능 |
☁ 데이터의 독립성 (↔ 종속성)
| 논리적 독립성 | 응용 프로그램과 데이터베이스르 독립시킴으로써, 데이터의 논리적 구조를 변경시키더라도 응용 프로그램은 영향 X |
| 물리적 독립성 | 응용 프로그램과 보조기억장치 같은 물리적 장치를 독립시킴으로써, 디스크를 추가/변경하더라도 응용 프로그램은 영향 X |
☁ 스키마 (Schema)
· 데이터베이스의 구조와 제약조건에 관한 전반적인 명세를 기술한 것
| 종 류 | 내 용 |
| 외부 스키마 | · 사용자나 응용 프로그래머가 각 개인의 입장에서 필요로 하는 데이터베이스의 논리적 구조를 정의한 것 |
| 개념 스키마 | · 데이터베이스의 전체적인 논리적 구조 · 모든 응용 프로그램이나 사용자들이 필요로 하는 데이터를 종합한 조직 전체의 데이터베이스로, 하나만 존재함 |
| 내부 스키마 | · 물리적 저장장치의 입장에서 본 데이터베이스 구조 · 실제로 저장될 레코드의 형식, 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 나타냄 |
( 2 ) 데이터베이스 설계
☁ 데이터베이스 설계 시 고려사항
| 항 목 | 내 용 |
| 무결성 | · 삽입, 삭제, 갱신 등의 연산 후에도 데이터베이스에 저장된 데이터가 정해진 제약 조건을 항상 만족해야 함 |
| 일관성 | · 데이터베이스에 저장된 데이터들 사이나, 특정 질의에 대한 응답이 처음부터 끝까지 변함없이 일정해야 함 |
| 회복 | · 시스템에 장애가 발생했을 때, 장애 발생 직전의 상태로 복구할 수 있어야 함 |
| 보안 | · 불법적인 데이터의 노출 또는 변경이나 손실로부터 보호할 수 있어야 함 |
| 효율성 | · 응답시간의 단축, 시스템의 생산성, 저장 공간의 최적화 등이 가능해야 함 |
| 데이터베이스 확장 | · 데이터베이스 운영에 영향을 주지 않으면서 지속적으로 데이터를 추가할 수 있어야 함 |
☁ 데이터베이스 설계 순서
| 1. 요구 조건 분석 | · 요구 조건 명세서 작성 |
| 2. 개념적 설계 | · 개념 스키마, 트랜잭션 모델링, E-R 모델 |
| 3. 논리적 설계 | · 목표 DBMS에 맞는 논리 스키마 설계, 트랜잭션 인터페이스 설계 |
| 4. 물리적 설계 | · 목표 DBMS에 맞는 물리적 구조의 데이터로 변환 |
| 5. 구현 | · 목표 DBMS의 DDL(데이터 정의어)로 데이터베이스 생성, 트랜잭션 작성 |
☁ 요구조건 분석
· 데이터베이스를 사용할 사람들로부터 필요한 용도를 파악하는 것
· 수집된 정보를 바탕으로 요구 조건 명세를 작성한다.
☁ 개념적 설계 (정보 모델링, 개념화)
· 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
· 개념 스키마 모델링과 트랜잭션 모델링을 병행 수행
· E-R 다이어그램으로 작성
· DBMS에 독립적인 개념 스키마를 설계
☁ 논리적 설계 (데이터 모델링)
· 현실 세계에서 발생하는 자료를 특정 DBMS가 지원하는 논리적 자료 구조로 변환(Mapping)시키는 과정
· 개념 스키마를 평가 및 정제하고 DBMS에 따라 서로 다른 논리적 스키마를 설계하는 단계
· 트랜잭션의 인터페이스를 설계
☁ 물리적 설계 (데이터 구조화)
· 논리적 구조로 표현된 데이터를 물리적 구조의 데이터로 변환하는 과정
· 데이터베이스 파일의 저장 구조 및 액세스 경로를 결정
· 데이터가 컴퓨터에 저장되는 방법을 묘사
☁ 데이터베이스 구현
· 논리적 설계와 물리적 설계에서 도출된 데이터베이스 스키마를 파일로 생성하는 과정
· 특정 DBMS의 DDL을 이용하여 데이터베이스 스키마를 기술한 후 컴파일하여 빈 데이터베이스 파일을 생성
· 응용 프로그램을 위한 트랜잭션을 작성
· 데이터베이스 접근을 위한 응용 프로그램을 작성
( 3 ) 데이터 모델의 개념
☁ 데이터 모델 (Data Model)
· 현실 세계의 정보들을 체계적으로 표현한 개념적 모형
· 데이터, 데이터의 관계, 데이터의 의미 및 일관성, 제약 조건 등을 기술하기 위한 개념적 도구들로 구성되어 있음
· 데이터베이스 설계 과정에서 데이터의 구조(Schema)를 논리적으로 표현하기 위해 지능적 도구로 사용됨
· 데이터 모델 구성 요소 : 개체, 속성, 관계
· 데이터 모델 종류
▫ 개념적 데이터 모델 (= 정보 모델)
· 현실 세계에 대한 인간의 이해를 돕기 위해 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
· 속성들로 기술된 개체 타입과 이 개체 타입들 간의 관계를 이용하여 현실 세계를 표현함
· 대표적인 개념적 데이터 모델 : E-R 모델
▫ 논리적 데이터 모델
· 개념적 구조를 컴퓨터 세계의 환경에 맞도록 변환하는 과정
· 필드로 기술된 데이터 타입과 이 데이터 타입들 간의 관계를 이용하여 현실 세계를 표현함
· 단순히 '데이터 모델'이라 하면 '논리적 데이터 모델'을 의미함
▫ 물리적 데이터 모델
· 데이터 모델에 표시할 요소 : (구연제)
| 요 소 | 내 용 |
| 구조 (Structure) | · 논리적으로 표현된 개체 타입들 간의 관계로서 데이터 구조 및 정적 성질 표현 |
| 연산 (Operation) | · 데이터베이스에 저장된 실제 데이터를 처리하는 작업에 대한 명세로서 데이터베이스를 조작하는 기본 도구 |
| 제약 조건 (Constraint) | · 데이터베이스에 저장될 수 있는 실제 데이터의 논리적인 제약 조건 |
( 4 ) E - R (개체-관계) 모델
☁ E-R (Entity - Relationship, 개체-관계) 모델
· 개체와 개체 간의 관계를 기본 요소로 이용하여 현실 세계의 무질서한 데이터를 개념적인 논리 데이터로 표현하기 위한 방법
· 개념적 데이터 모델의 가장 대표적인 것 ➡ 개체 타입과 이들 간의 관계 타입을 이용해 현실 세계를 개념적으로 표현
· 데이터를 개체(Entity), 속성(Attribute), 관계(Relationship)로 묘사
· 1:1, 1:N, N:M 등의 관계 유형을 제한 없이 나타낼 수 있음
☁ E-R (Entity - Relationship, 개체-관계) 모델
| 기 호 | 기호 이름 | 의 미 |
 |
사각형 | 개체(Entity) 타입 |
 |
마름모 | 관계(Relationship) 타입 |
 |
타원 | 속성(Attribute) |
 |
이중 타원 | 다중값 속성(복합 속성) |
 |
밑줄 타원 | 기본키 속성 |
 |
복수 타원 | 복합 속성 ex. 성명은 성과 이름으로 구성 |
 |
관계 | 1:1, 1:N, N:M 등의 개체 간 관계에 대한 대응수를 선 위에 기술함 |
 |
선, 링크 | 개체 타입과 속성을 연결 |
( 5 ) 관계형 데이터베이스의 구조 / 관계형 데이터 모델
☁ 관계형 데이터베이스
· 2차원 적인 표(table)를 이용해서 데이터 상호 관계를 정의하는 데이터베이스
· 개체와 관계를 모두 릴레이션(Relation)이라는 표(Table)로 표현하기 때문에 개체를 개체 릴레이션과 관계 릴레이션이 존재
· 장점 : 간결하고 보기 편리, 다른 데이터베이스로의 변환이 용이
· 단점 : 성능이 다소 떨어짐
☁ 관계형 데이터베이스의 릴레이션 구조
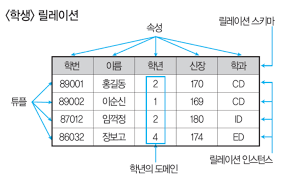
☁ 튜플 (Tuple)
· 릴레이션을 구성하는 각각의 행
· 속성의 모임으로 구성
· 파일 구조에서 레코드와 같은 의미
· 튜플의 수 : 카디널리티 (Cardinality) 또는 기수, 대응수
☁ 속성 (Attribute)
· 데이터베이스를 구성하는 가장 작은 논리적 단위
· 파일 구조상의 데이터 항목 또는 데이터 필드에 해당
· 개체의 특성을 기술
· 속성의 수 : 디그리(Degree) 또는 차수
☁ 도메인 (Domain)
· 하나의 속성(Attribute)이 취할 수 있는 같은 타입의 원자(Atomic) 값들의 집합
· 실제 속성의 값이 나타날 때, 그 값의 합법 여부를 시스템이 검사하는 데에도 이용됨
ex ) '성별' 속성의 도메인은 '남'과 '여'로, 그 외의 값은 입력될 수 없음
☁ 릴레이션의 특징
· 한 릴레이션에는 똑같은 튜플이 포함될 수 없으므로 릴레이션에 포함된 튜플들은 모두 상이함
· 한 릴레이션에 포함된 튜플 사이에는 순서가 없다.
· 튜플들의 삽입, 삭제 등의 작업으로 인해 릴레이션은 시간에 따라 변한다.
· 릴레이션 스키마를 구성하는 속성들 간의 순서는 중요하지 않다.
· 속성의 유일한 식별을 위해 속성의 명칭은 유일해야 하지만, 속성을 구성하는 값은 동일한 값이 있을 수 있다.
· 릴레이션을 구성하는 튜플을 유일하게 식별하기 위해 속성들의 부분집합을 키(Key)로 설정한다.
· 속성의 값은 논리적으로 더 이상 쪼갤 수 없는 원자값만을 저장한다.
☁ 관계형 데이터 모델 (Relational Data Model)
· 2차원적인 표(Table)를 이용해서 데이터 상호 관계를 정의하는 DB 구조
· 가장 널리 사용되는 데이터 모델
· 기본키(Primary Key)와 이를 참조하는 외래키(Foreign Key)로 데이터 간의 관계를 표현
· 계층 모델과 망 모델의 복잡한 구조를 단순화시킨 모델
· 관계형 모델의 대표적인 언어는 SQL
· 1:1, 1:N, N:M 관계를 자유롭게 표현할 수 있다.
☁ 키 (Key)
· 데이터베이스에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 기준이 되는 속성
· 종류
▫ 후보키 (Candidate Key)
· 속성들 중에서 튜플을 유일하게 식별하기 위해 사용되는 속성들의 부분집합
· 기본키로 사용할 수 있는 속성들
· 유일성(Unique)과 최소성(Minimality)을 모두 만족시켜야 한다.
| 유일성(Unique) | · 하나의 키 값으로 하나의 튜플만을 유일하게 식별할 수 있어야 함 |
| 최소성(Minimality) | · 키를 구성하는 속성 하나를 제거하면 유일하게 식별할 수 없도록 꼭 필요한 최소의 속성으로 구성되어야 함 |
▫ 기본키 (Primary Key)
· 후보키 중에서 특별히 선정된 주키(Main Key)
· 중복된 값을 가질 수 없다.
· 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
· NULL 값을 가질 수 없다.
▫ 대체키 (Alternate Key, 보조키)
· 후보키가 둘 이상일 때, 기본키를 제외한 나머지 후보키
▫ 슈퍼키 (Super Key)
· 속성들의 집합으로 구성된 키
· 모든 튜플에 대해 유일성은 만족하지만, 최소성은 만족하지 못함
▫ 외래키 (Foreign Key)
· 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합
☁ 무결성 (Integrity)
· 데이터베이스에 저장된 데이터 값과 현실 세계의 실제값이 일치하는 정확성
· 데이터베이스에 들어있는 데이터의 정확성을 보장하기 위해 부정확한 자료가 데이터베이스 내에 저장되는 것을 방지하기 위한 제약 조건
| 종 류 | 내 용 |
| 개체 무결성 | · 기본키를 구성하는 어떤 속성도 Null 값이나 중복값을 가질 수 없다. |
| 참조 무결성 | · 외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 함 즉, 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다. |
| 도메인 무결성 | · 주어진 속성 값이 정의된 도메인에 속한 값이어야 한다. |
| 사용자 정의 무결성 | · 속성 값들이 사용자가 정의한 제약 조건에 만족되어야 한다. |
| NULL 무결성 | · 릴레이션의 특정 속성 값이 Null이 될 수 없도록 하는 규정 |
| 고유 무결성 | · 릴레이션의 특정 속성에 대해 각 튜플이 갖는 속성 값들이 서로 달라야 한다. |
| 키 무결성 | · 하나의 릴레이션에는 적어도 하나의 키가 존재해야 한다. |
| 관계 무결성 | · 릴레이션에 어느 한 튜플의 삽입 가능 여부 또는 한 릴레이션과 다른 릴레이션의 튜플들 사이의 관계에 대한 적절성 여부를 지정한 규정 |
☁ 관계대수
· 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적인 언어
· 릴레이션을 처리하기 위해 연산자와 연산 규칙을 제공하며, 피연산자와 연산 결과가 모두 릴레이션이다.
· 질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시함
◽ 순수 관계 연산자 (셀프조디)
| 종 류 | 특 징 | 기 호 |
| Select | · 튜플 중 선택 조건을 만족하는 튜플의 부분 집합을 구하여 새로운 릴레이션을 만드는 연산 · 수평 연산이라고도 함 |
σ(시그마) |
| Project | · 속성 리스트에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만드는 연산 · 수직 연산자라고도 함 |
π(파이) |
| Join | · 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산 · Join의 결과는 Cartesian Product(교차곱)를 수행한 다음 Select를 수행한 것과 같음 |
⋈ |
| Division | · X⊃Y인 두 개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산 |
÷ |
◽ 일반 집합 연산자 (합교차카)
| 종 류 | 특 징 | 기 호 |
| UNION |
· 두 릴레이션에 존재하는 튜플의 합집합을 구하는 연산 (중복되는 튜플은 제거) · | R ∪ S | ≤ | R | + | S | (합집합의 Cardinality): 두 릴레이션의 합보다 크지 않음 |
∪ |
| INTERSECTION |
· 두 릴레이션에 존재하는 튜플의 교집합을 구하는 연산 ·| R ∩ S | ≤ MIN{ | R | , | S | } (교집합의 Cardinality): 두 릴레이션 중 카디널리티가 적은 릴레이션의 카디널리티보다 크지 않음 |
∩ |
| DIFFERENCE |
· 두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산 · | R ─ S | ≤ | R | (차집합의 Cardinality): 릴레이션 R의 카디널리티보다 크지 않음 |
━ |
| CARTESIAN PRODUCT |
· 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산 · | R X S | ≤ | R | X | S | : 교차곱은 두 릴레이션의 카디널리티를 곱한 것과 같음 |
X |
☁ 관계해석
· 관계 데이터의 연산을 표현하는 방법
· 원하는 정보가 무엇이라는 것만 정의하는 비절차적 특성을 지님
· 원하는 정보를 정의할 때는 계산 수식을 사용
( 6 ) 정규화 (Normalization)
· 테이블의 속성들이 상호 종속적인 관계를 갖는 특성을 이용하여 테이블을 무손실 분해하는 과정
· 목적 : 가능한 한 중복을 제거하여 삽입, 삭제, 갱신 이상의 발생 가능성을 줄이는 것
☁ 제 1정규형 (1NF)
· 모든 속성의 도메인(Domain)이 원자 값(Atomic Value)만으로 되어 있는 정규형
· 즉, 테이블의 모든 속성 값이 원자 값으로만 되어 있는 정규형
☁ 제 2정규형 (2NF)
· 기본키가 아닌 모든 속성이 기본키에 대하여 완전 함수적 종속을 만족하는 정규형
☁ 제 3정규형 (3NF)
· 기본키가 아닌 모든 속성이 기본키에 대해 이행적 함수적 종속(Transitive Functional Dependency)을 만족하지 않는 정규형
◽ 이행적 함수적 종속
A➡ B이고, B➡C일 때, A➡C를 만족하는 관계
☁ BCNF
· 모든 결정자가 후보키(Candidate Key)인 정규형
☁ 제 4정규형 (4NF)
· 다중 값 종속(MVD; Multi Valued Dependency) A➡B가 존재할 경우, R의 모든 속성이 A에 함수적 종속 관계를 만족하는 정규형
◽ 다중 값 종속
A, B, C 3개의 속성을 가진 테이블 R에서 어떤 복합 속성(A, C)에 대응하는 B 값의 집합이 A 값에만 종속되고 C 값에는 무관하면,
B는 A에 다중 값 종속이라 하고, A➡B로 표기함
☁ 제 5정규형 (5NF)
· 모든 조인 종속(JD; Join Dependency)이 R의 후보키를 통해서만 성립되는 정규형
◽ 조인 종속
어떤 테이블 R의 속성에 대한 부분 집합 X, Y, …, Z가 있다고 가정하자.
이 때 만일 테이블 R이 자신의 프로젝션(Projection) X, Y, …, Z를 모두 조인한 결과와 동일한 경우
테이블 R은 조인 종속 JD(X, Y, …, Z)를 만족한다고 한다.
( 7 ) 반정규화 (Denormalization)
· 정규화된 데이터 모델을 의도적으로 통합, 중복, 분리하여 정규화 원칙을 위배하는 행위
· 장점 : 시스템의 성능 향상, 관리 효율성 증가
· 단점 : 데이터의 일관성 및 정합성 저하 우려 O
☁ 테이블 통합
· 두 개의 테이블이 Join되어 사용되는 경우가 많을 경우, 성능 향상을 위해 아예 하나의 테이블로 만들어 사용하는 것
· 종류 : 1:1 / 1:N / 슈퍼타입,서브타입 관계 테이블 통합
☁ 테이블 분할
· 테이블을 수직 또는 수평으로 분할하는 것
| 방 법 | 내 용 |
| 수평 분할 | · 레코드(Record)를 기준으로 테이블을 분할하는 것 · 레코드별로 사용 빈도의 차이가 큰 경우 사용 빈도에 따라 테이블을 분할함 |
| 수직 분할 | · 하나의 테이블에 속성이 너무 많을 경우 속성을 기준으로 테이블을 분할하는 것 |
☁ 중복 테이블 추가 (집진특)
· 작업의 효율성을 향상시키기 위해 테이블을 추가하는 것
· 여러 테이블에서 데이터를 추출해서 사용해야 할 경우 / 다른 서버에 저장된 테이블을 이용해야 하는 경우
| 집계 테이블의 추가 | · 집계 데이터를 위한 테이블을 생성하고, 각 원본 테이블에 Trigger를 설정하여 사용하는 것 |
| 진행 테이블의 추가 | · 이력 관리 등의 목적으로 추가하는 테이블 |
| 특정 부분만을 포함하는 테이블의 추가 | · 데이터가 많은 테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블 생성 |
☁ 중복 속성 추가
· 조인해서 데이터를 처리할 때 데이터를 조회하는 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것
· 데이터의 무결성 확보가 어렵고, 디스크 공간이 추가로 필요
· 조인이 자주 발생하는 경우 / 접근 경로가 복잡한 속성인 경우 / 액세스의 조건으로 자주 사용되는 속성인 경우
( 8 ) 트랜잭션 분석 / CRUD 분석
☁ 트랜잭션 (Transaction)
· 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산
· 데이터베이스 시스템에서 병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위로 사용됨
· 사용자가 시스템에 대한 서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업 단위로 사용
☁ 트랜잭션의 특성 (ACID)
| 특 성 | 의 미 |
| Atomicity (원자성) | · 트랜잭션의 연산은 모두 반영되도록 완료(Commit) 또는 반영되지 않도록 복구(Rollback)돼야 함 |
| Consistency (일관성) | · 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환 |
| Isolation (독립성, 격리성, 순차성) | · 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우, 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없음 |
| Durability (영속성, 지속성) | · 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 함 |
☁ CRUD 분석
· 프로세스와 테이블 간에 CRUD 매트릭스를 만들어서 트랜잭션을 분석하는 것
· 많은 트랜잭션이 몰리는 테이블을 파악할 수 있으므로, 디스크 구성 시 유용한 자료로 활용할 수 있음
☁ 트랜잭션 분석
· CRUD 매트릭스를 기반으로 테이블에 발생하는 트랜잭션 양을 분석하여 테이블에 저장되는 데이터의 양을 유추하고,
이를 근거로 DB의 용량 산정 및 구조의 최적화를 목적으로 함
· 업무 개발 담당자가 수행
( 9 ) View / Cluster
☁ View
· 하나 이상의 기본 테이블로부터 유도된 가상 테이블
· 저장 장치 내에 물리적으로 존재하지 않지만, 사용자에게는 있는 것처럼 간주됨
· 뷰 정의 시에는 CREATE문, 제거할 때는 DROP문을 사용
| 장 점 | 단 점 |
| · 논리적 데이터 독립성을 제공 · 동일 데이터에 대해 동시에 여러 사용자의 상이한 응용이나 요구를 지원해 줌 · 사용자의 데이터 관리를 간단하게 해줌 · 접근 제어를 통한 자동 보안이 제공됨 |
· 독립적인 인덱스를 가질 수 없음 · 뷰의 정의를 변경할 수 없음 · 뷰로 구성된 내용에 대한 삽입, 삭제, 갱신 연산에 제약이 따름 |
☁ Cluster (클러스터)
· 동일한 성격의 데이터를 동일한 데이터 블록에 저장하는 물리적 저장 방법
· 클러스터링 된 테이블은 데이터 조회 속도를 향상시키지만, 입력·수정·삭제에 대한 작업 성능을 저하시킴
· 데이터의 분포도가 넓을 수록 유리
· 처리 범위가 넓은 경우에는 단일 테이블 클러스터링 / 조인이 많이 발생하는 경우에는 다중 테이블 클러스터링을 사용
( 9 ) 분산 데이터베이스 설계
· 논리적으로는 하나의 시스템에 속하지만 물리적으로는 네트워크를 통해 연결된 여러 개의 사이트(Site)에 분산된 데이터베이스
· 데이터의 처리나 이용이 많은 지역에 데이터베이스를 위치시킴으로써 데이터의 처리가 가능한 해당 지역에서 해결될 수 있도록 함
· 목적 : 애플리케이션이나 사용자가 분산되어 저장된 데이터에 접근하게 하는 것
☁ 분산 데이터베이스의 목표
| 위치 투명성 (Location Transparency) |
· 접근하려는 데이터베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적인 명칭만으로 액세스할 수 있다. |
| 중복 투명성 (Replication Transparency) |
· 동일 데이터가 여러 곳에 중복되어 있더라도 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용하고, 시스템은 자동으로 여러 자료에 대한 작업을 수행함 |
| 병행 투명성 (Concurrency Transparency) |
· 분산 데이터베이스와 관련된 다수의 트랜잭션들이 동시에 실행되더라도 그 트랜잭션의 결과는 영향을 받지 않음 |
| 장애 투명성 (Failure Transparency) |
· 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 불구하고 트랜잭션을 정확하게 처리함 |
( 10 ) 자료 구조
· 자료를 기억장치의 공간 내에 저장하는 방법과 자료 간의 관계, 처리 방법 등을 연구 분석하는 것
· 저장 공간의 효율성과 실행 시간의 단축을 위해 사용함
☁ 배열 (Array)
· 크기와 형(Type)이 동일한 자료들이 순서대로 나열된 자료의 집합
· 반복적인 데이터 처리 작업에 적합한 구조
· 정적인 자료 구조로, 기억 장소의 추가가 어려움
· 데이터 삭제 시, 기억장소가 빈 공간으로 남아있어 메모리의 낭비가 발생함
· 정적인 자료 구조로, 기억 장소의 추가가 어려움
☁ 연속 리스트 (Contiguous List)
· 연속되는 기억장소에 저장되는 자료 구조
· 중간에 데이터를 삽입하기 위해서는 연속된 빈 공간이 있어야 함
· 삽입·삭제 시 자료의 이동이 필요함
· 데이터 삭제 시, 기억장소가 빈 공간으로 남아있어 메모리의 낭비가 발생함
· 정적인 자료 구조로, 기억 장소의 추가가 어려움
☁ 연결 리스트 (Linked List)
· 자료들을 임의의 기억공간에 기억시키되, 노드의 포인터 부분을 이용하여 서로 연결시킨 자료 구조
· 연결을 위한 링크(포인터) 부분이 필요하기 때문에 기억 공간의 이용 효율이 좋지 않다.
· 접근 속도가 느리고, 연결이 끊어지면 다음 노드를 찾기 어려움
☁ 스택 (Stack)
· 리스트의 한 쪽 끝으로만 자료의 삽입, 삭제 작업이 이뤄지는 자료 구조
· 후입선출(LIFO; Last In First Out) 방식
· 저장할 기억 공간이 없는 상태에서 데이터가 삽입되면 오버플로(Overflow)가 발생
· 삭제할 데이터가 없는 상태에서 데이터를 삭제하면 언더플로(Underflow)가 발생
☁ 큐 (Queue)
· 리스트의 한 쪽에서는 삽입 작업, 다른 한 쪽에서는 삭제 작업이 이뤄지는 자료 구조
· 선입선출(FIFO; First In First Out) 방식
· 시작을 표시하는 프런트(Front) 포인터와 끝을 표시하는 리어(Rear) 포인터가 있음
☁ 그래프(Graph)
· 정점(Vertex)과 간선(Edge)의 두 집합으로 이뤄지는 자료 구조
· 사이클이 없는 그래프를 트리(Tree)라고 함
· 간선의 방향성 유무에 따라 방향 그래프와 무방향 그래프로 구분
◽ 방향/ 무방향 그래프
- 방향 그래프의 최대 간선 수 : n(n-1)
- 무방향 그래프의 최대 간선 수 : n(n-1) / 2
☁ 트리 (Tree)
· 정점(Node, 노드)과 선분(Branch, 가지)을 이용하여 사이클을 이루지 않도록 구성한 그래프의 특수한 형태
· 하나의 기억 공간을 노드(Node)라고 하며, 노드와 노드를 연결하는 선을 링크(Link)라고 함

| 노드(Node) | · 트리의 기본 요소 · 자료 항목과 다른 항목에 대한 가지(Branch)를 합친 것 ex. A, B, C, D, E, F, G, H, I, J, K, L, M |
| 근 노드(Root Node) | · 트리의 맨 위에 있는 노드 ex. A |
| 디그리 (Degree, 차수) | · 각 노드에서 뻗어나온 가지의 수 ex. A = 3, B = 2, C =1 |
| 단말 노드 (Terminal Node) = 잎 노드 (Leaf Node) |
· 자식이 하나도 없는 노드, 즉 Degree가 0인 노드 ex. K, L, F, G, M, I, J |
| 비단말 노드 (Non-Terminal Node) | · 자식이 하나라도 있는 노드, 즉 Degree가 0이 아닌 노드 ex. A, B, C, D, E, H |
| 조상 노드 (Ancestors Node) | · 임의의 노드에서 근 노드에 이르는 경로상에 있는 노드들 ex. M의 조상 노드 : H, D, A |
| 자식 노드 (Son Node) | · 어떤 노드에 연결된 다음 레벨의 노드들 ex. D의 자식 노드 : H, I, J |
| 부모 노드 (Parent Node) | · 어떤 노드에 연결된 이전 레벨의 노드들 ex. E, F의 부모 노드 : B |
| 형제 노드 (Brother Node, Sibling) | · 동일한 부모를 갖는 노드들 ex. H의 형제 노드 : I, J |
| Level | · 근 드의 Level을 1로 가정한 후 어떤 Level이 L이면 자식 노드는 L + 1 ex. H의 레벨은 3 |
| 깊이 (Depth, Height) | · Tree에서 노드가 가질 수 있는 최대의 레벨 ex. 위 트리의 깊이는 4 |
| 숲 (Forest) | · 여러 개의 트리가 모여 있는 것 ex. 위 트리에서 근 노드 A를 제거하면, B, C, D를 근 노드로 하는 세개의 트리가 있는 숲이 생김 |
| 트리의 디그리 | · 노드들의 디그리 중에서 가장 많은 수 ex. 노드 A나 D가 세 개의 디그리를 가지므로 위 트리의 디그리는 3 |
☁ 이진 트리 (Binary Tree)
· 차수(Degree)가 2 이하인 노드들로 구성된 트리
· 즉, 자식이 둘 이하인 노드들로만 구성된 트리
◽ 트리의 운행법 (Traversal)
| Preorder 운행법 | Root ➡ Left ➡ Right 순으로 운행 |
| Inorder 운행법 | Left ➡ Root ➡ Right 순으로 운행 |
| Postorder 운행법 | Left ➡ Rigth ➡ Root 순으로 운행 |
( 11 ) 정렬 (Sort)
☁ 삽입 정렬 (Insertion Sort)
· 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬하는 방식
· 평균과 최악 모두 수행 시간 복잡도는 O(n²)
☁ 선택 정렬 (Selection Sort)
· 최소값을 찾아 첫 번째 레코드 위치에 놓고, 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하여 정렬하는 방식
· 평균과 최악 모두 수행 시간 복잡도는 O(n²)
☁ 버블 정렬 (Bubble Sort)
· 인접한 두 개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식
· 평균과 최악 모두 수행 시간 복잡도는 O(n²)
☁ 쉘 정렬 (Shell Sort)
· 매개변수의 값으로 서브파일을 구성하고, 각 서브파일을 Insertion 정렬 방식으로 순서 배열하는 정렬 방식
· 삽입 정렬(Insertion Sort)을 확장한 개념
· 평균 수행 시간 복잡도는 O(n^1.5), 최악의 수행 시간 복잡도는 O(n²)
☁ 퀵 정렬 (Quick Sort)
· 키를 기준으로 작은 값은 왼쪽, 큰 값은 오른쪽 서브 파일에 분해시키는 정렬 방식
· 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나눠 가면서 정렬함
· 평균 수행 시간 복잡도는 O(nlog₂n), 최악의 수행 시간 복잡도는 O(n²)
☁ 힙 정렬 (Heap Sort)
· 전이진 트리를 이용한 정렬 방식
· 구성도니 전이진 트리(Complete Binary Tree)를 Heap Tree로 변환하여 정렬
· 평균과 최악 모두 시간 복잡도는 O(nlog₂n)
☁ 2-Way 합병 정렬 (Merge Sort)
· 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식
· 평균과 최악 모두 시간 복잡도는 O(nlog₂n)
☁ 기수 정렬 (Radix Sort) = Bucket Sort
· Queue를 이용하여 자릿수(Digit)별로 정렬하는 방식
· 레코드의 키 값을 분석하여 같은 수 또는 같은 문자끼리 그 순서에 맞는 버킷에 분배하였다가 버킷의 순서대로 레코드를 꺼내어 정렬
· 평균과 최악 모두 시간 복잡도는 O(dn)
Ref.
시나공 정보처리기사실기 책
'Certification > 정보처리기사' 카테고리의 다른 글
| [ 정보처리기사 실기 요약 ] 4. 서버 프로그램 구현 (0) | 2023.03.08 |
|---|---|
| [ 정보처리기사 실기 요약 ] 1. 요구사항 확인 (0) | 2023.03.02 |
| [ 정보처리기사 실기 ] 0. 2023 정보처리기사 실기 요약 (0) | 2023.03.01 |

